OPENING HOOK多个第三方观察,指向同一个问题
先看两份外部证据
同一个模型,
同一个模型,
不等于同一个工程能力
从早期网文观察,到 Composer 2.5 出来后的第三方 benchmark,大家开始测的不只是模型,而是完整 Coding Agent。
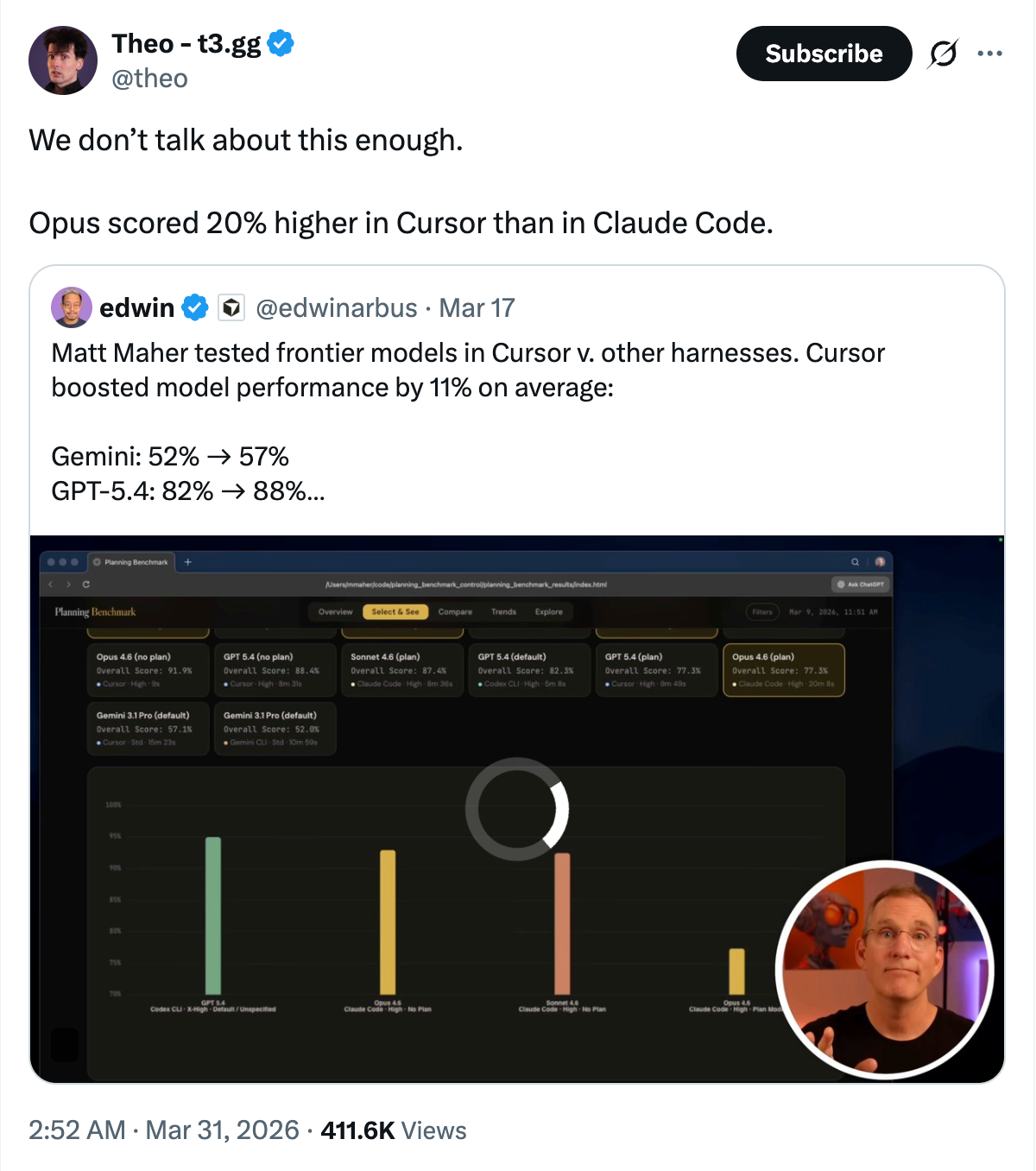
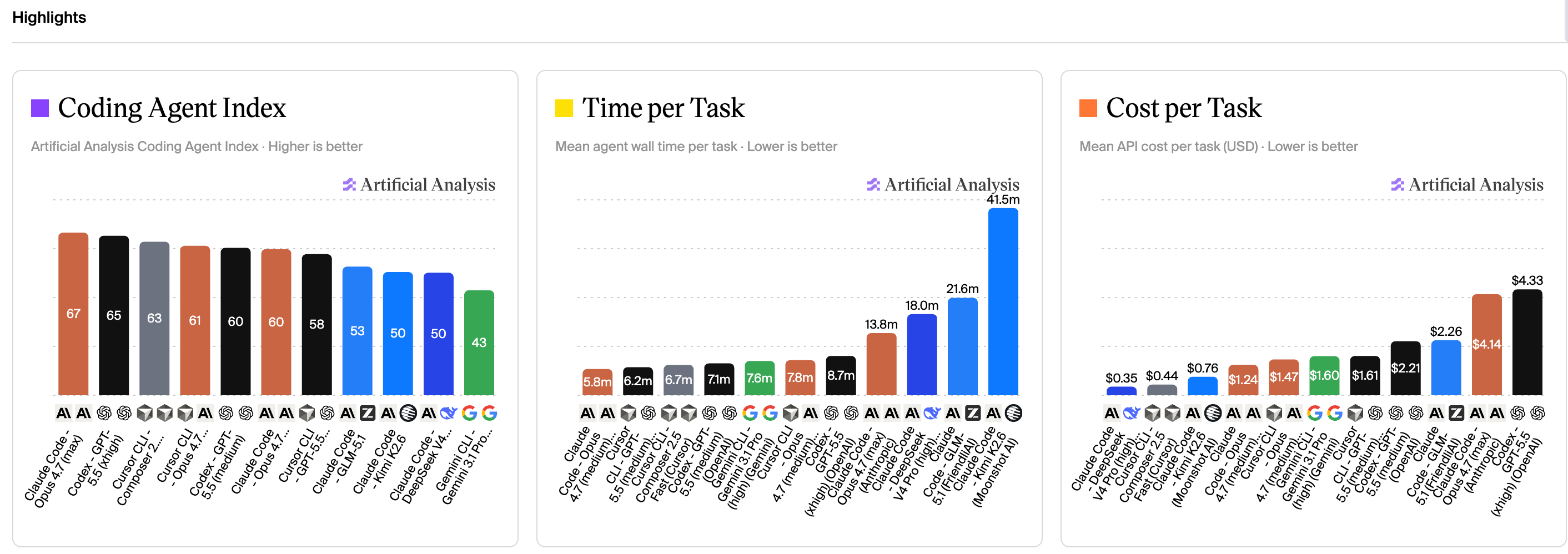
今天的重点不是“谁第一”,而是:模型之外的上下文、工具、成本、时间和反馈链路,正在一起决定结果。
按 → 依次展示第三方证据 · then thesis
SOURCE · INSIDE CURSOR@zebriez · 190万+ views
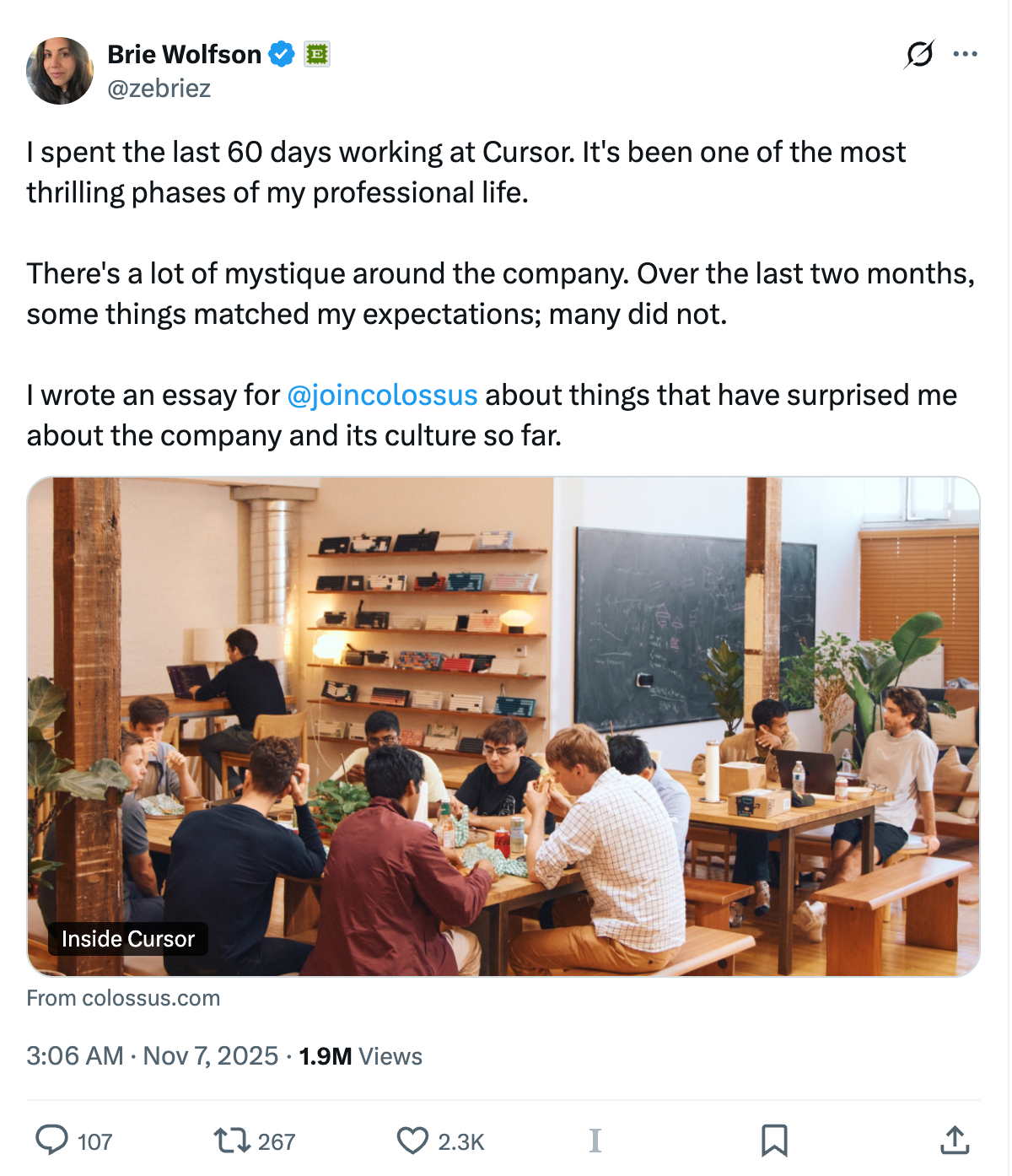
@zebriez on X · Inside Cursor
深度观察 60 天
01Dogfooding(吃自己的狗粮)团队每天用 Cursor 做真实工作;产品能力从真实工作流里长出来,功能先被内部压力测试再 ship。
02Talent Density招聘像迭代产品;顶级 IC 密度本身,就是交付速度的一部分。
03Raise the ceiling先抬高上限,再降低门槛——优先满足高水平 builder 的能力诉求。
SOURCE · x.com/zebriez/status/1986510506199556395 · colossus.com/article/inside-cursor
CULTURE THREAD · 1/2从文化到工作方式

REFERENCE · Apple product culture
Culture becomes workflow
你怎么判断,
你怎么判断,
会变成团队默认
如何描述问题、选择证据、如何验收——强产品团队把这些写进日常协作。
BRIDGE · culture → dogfooding → product capability
CULTURE THREAD · 2/2文化即工作状态
Ben 把它做成网站
No-shoes.fun:a culture, not a policy
无拘无束、像在家一样、多元文化——No-shoes 说的是工作状态,不是 dress code。这种环境支撑敢试错,才撑得起 Dogfooding。

SOURCE · no-shoes.fun · Inside Cursor
MERKLE TREEEngineer's Codex
大仓库也要快
不用每次重扫整个代码库
索引的秘密很简单:只同步变化的部分——改过的文件、改过的代码块,不必全量重扫。Merkle Tree 是 Cursor 用来做到这一点的机制。
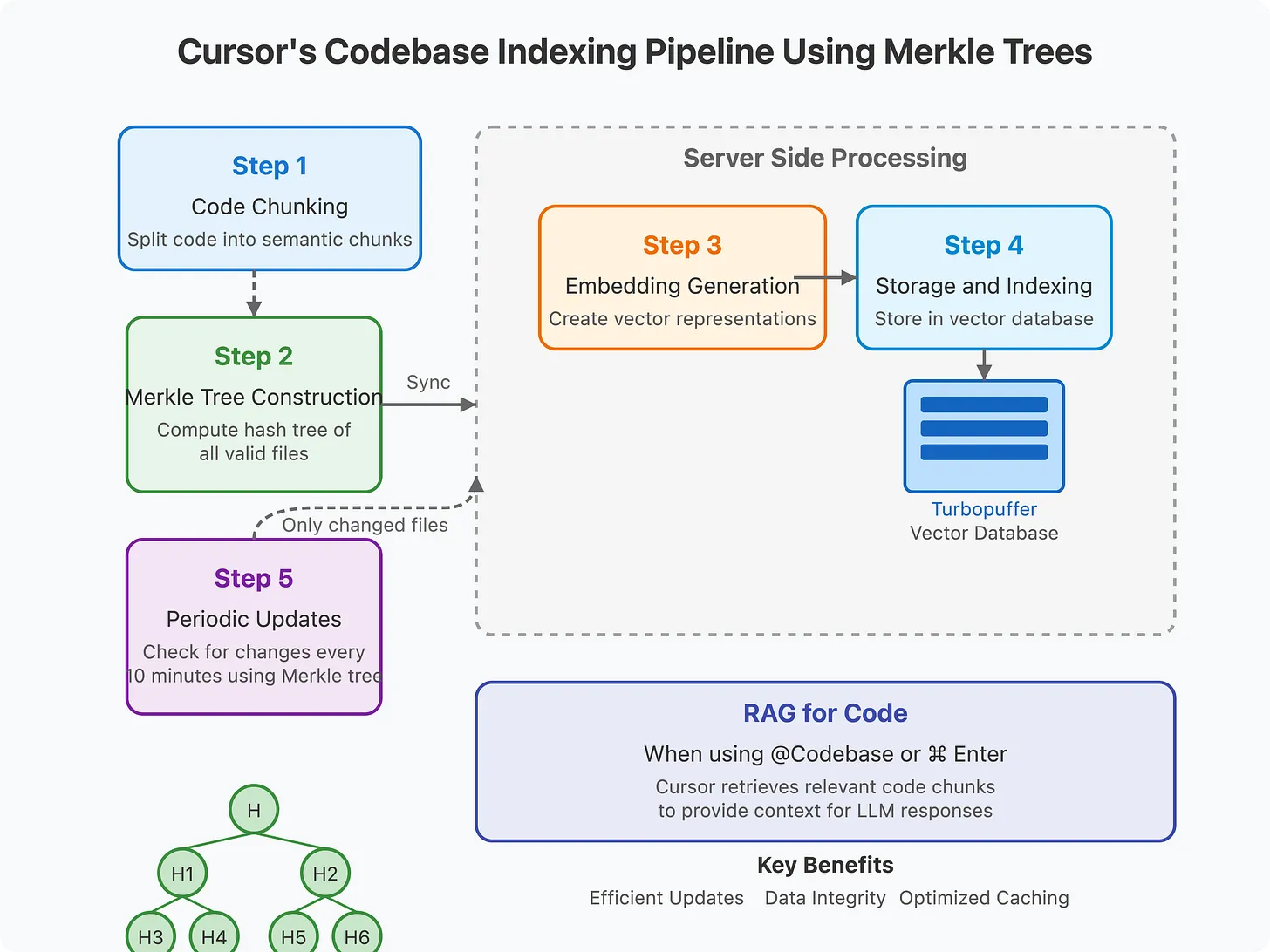
SOURCE · read.engineerscodex.com/p/how-cursor-indexes-codebases-fast
POINT · incremental sync, not brute force
SCREENSHOTCodebase Indexing
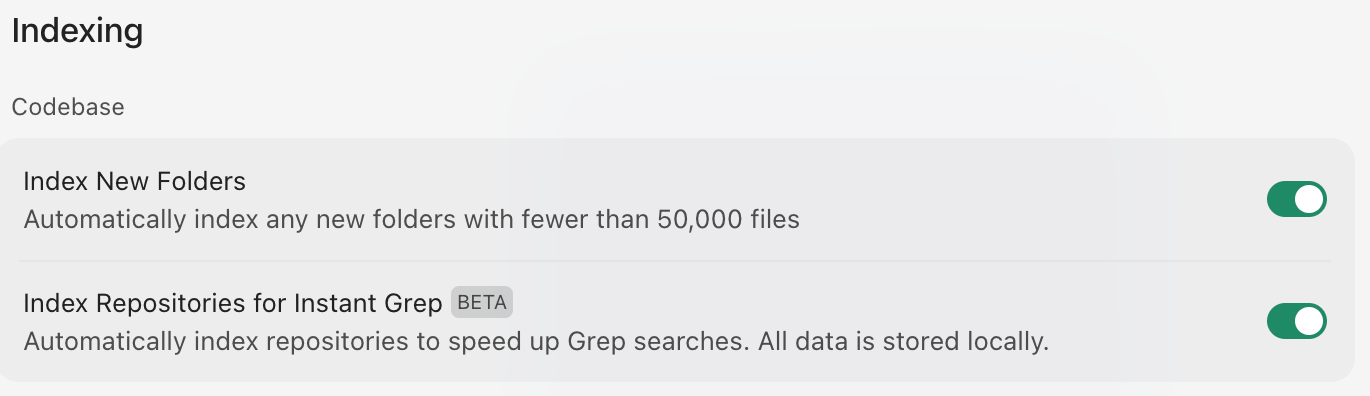
从工程能力落到产品界面
项目被索引后,Agent 才能按项目语境工作
代码结构、相似实现和历史变更进入可检索环境,模型才不必靠泛化经验猜测项目意图。
VISUAL · show the real product
SCREENSHOTInstant Grep
第二层能力:快速找事实
好 Agent 会先查代码,再动手
不是一上来就改文件——而是在任务推进中,用搜索、读文件、对照文档,验证理解后再改。
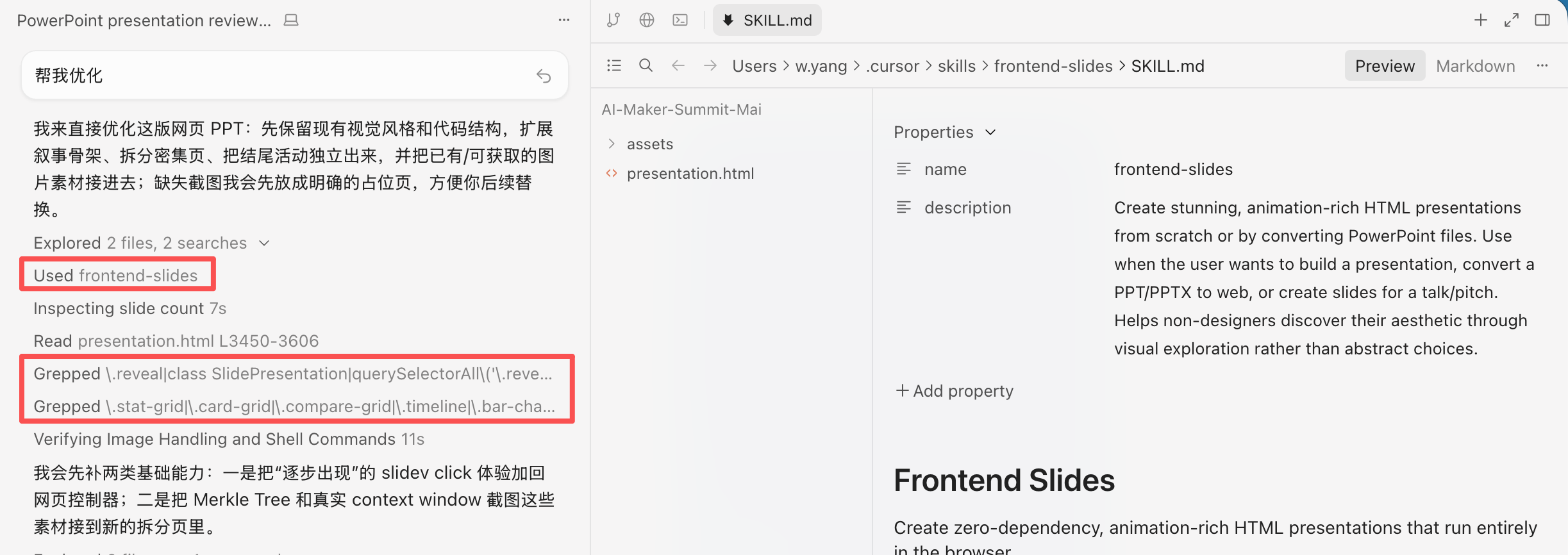
CAPABILITY · retrieve facts quickly
REAL SCREENSHOTyour actual context panel
抽象图之后,给真实证据
这就是一次真实会话的上下文账单
22% Full,约 61K / 272K tokens。Conversation 占 41.1K,Tools 占 10.5K。上下文窗口不是无限仓库,而是需要被管理的工作预算。
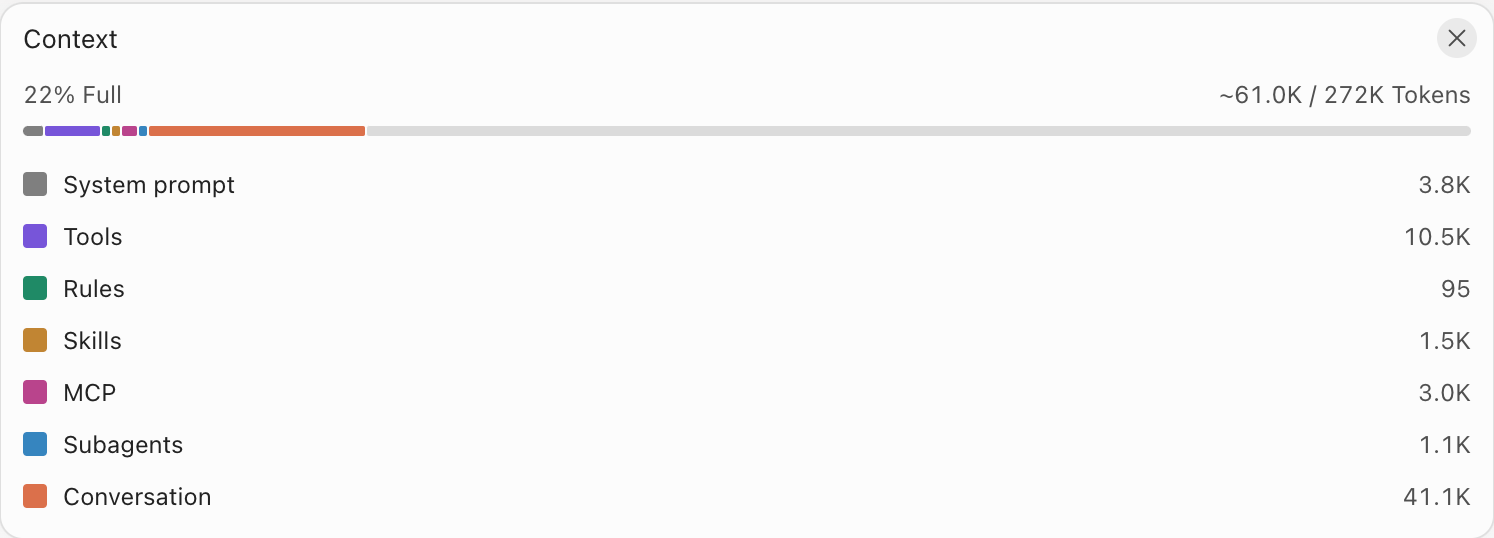
REAL SCREENSHOT · Context Window Breakdown
POINT · context is budget
CAFE CURSOR SHENZHEN2026.06.26
JOIN US · 一起聊聊
Cafe Cursor
Cafe Cursor
Shenzhen
2026.06.26 · Friday
如果今天分享让你产生共鸣,欢迎 6/26 来深圳 Cafe Cursor,面对面继续聊 AI Coding、Agent 工作流和 Builder 的新能力。
luma.com/cursorcommunity

COMMUNITY CTA
Cursor@summit:~$ open questions.md
Q & A
● END OF TALK